礦用廣播通訊系統與安全監控服務 構筑礦山安全避險的堅實屏障
在現代化礦山開采作業中,安全生產是永恒的主題。以“礦山安全避險六大系統”為核心,融合礦用廣播通訊系統、金屬礦山監控系統及新興的監控服務模式,共同構建了一個立體化、智能化的礦山安全防護體系,為礦工生命安全和礦山穩定運營提供了至關重要的保障。
一、礦山安全避險六大系統:生命安全的基石
“礦山安全避險六大系統”是國家為提升礦山安全保障能力強制推行的基礎性工程,主要包括:監測監控系統、井下人員定位系統、緊急避險系統、壓風自救系統、供水施救系統和通信聯絡系統。這六大系統互為補充,形成了從風險預警、人員定位到緊急逃生、生命支持的全鏈條防護。其中,通信聯絡系統是貫穿始終的“神經中樞”,而廣播通訊則是其實現高效信息傳遞的關鍵載體。
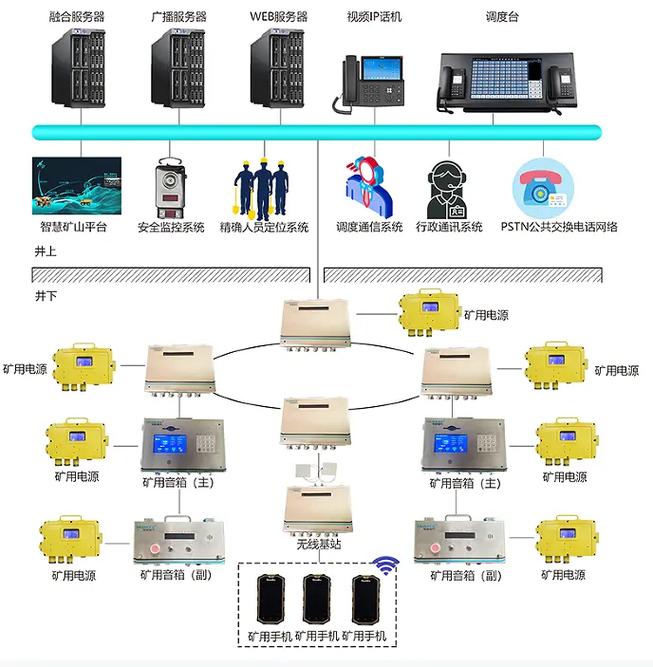
二、礦用廣播通訊系統:應急指揮的“擴音器”
礦用廣播通訊系統是專門為礦山復雜環境設計的通信解決方案。它具備以下核心功能與特點:
- 全覆蓋與強抗擾:系統信號能夠覆蓋井下巷道、作業面等所有區域,并具備強大的抗干擾能力,確保在惡劣環境下通信清晰、穩定。
- 分級廣播與應急聯動:支持全礦、區域、單點分級廣播,并能與監測監控、人員定位等系統聯動。一旦傳感器監測到瓦斯超限、透水、冒頂等險情,系統可自動觸發應急預案,向相關區域發布精準的語音警報和疏散指令。
- 雙向通信與調度指揮:不僅支持從上到下的廣播通知,也具備井下關鍵點位與調度中心的雙向對講功能,便于實時調度、核實情況與救援指揮。
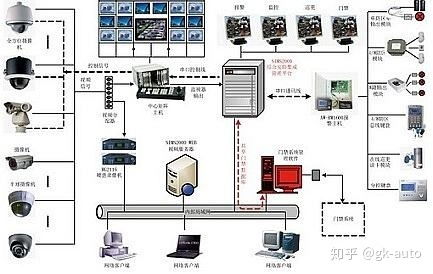
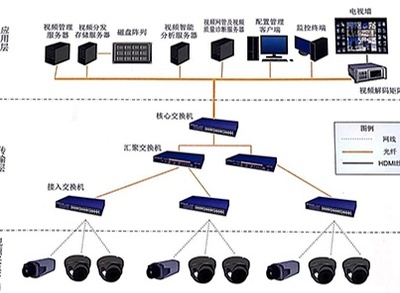
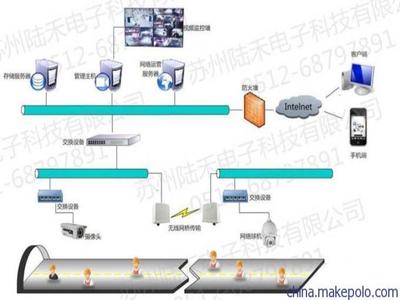
三、金屬礦山監控系統:全天候的“電子哨兵”
金屬礦山監控系統是礦山安全生產的“眼睛”和“大腦”。它通過集成視頻監控、環境參數監測(如地壓、位移、有毒有害氣體)、設備運行狀態監控等子系統,實現對礦山全方位、全時段的動態監控。
- 可視化監控:高清攝像頭布設在井口、巷道、關鍵設備等處,將現場畫面實時傳輸至調度中心,實現遠程可視化監管。
- 參數智能感知:各類傳感器實時采集環境安全數據,通過數據分析平臺進行智能分析,實現災害超前預測預警。
- 與廣播系統深度融合:監控系統發現的異常情況,可立即觸發廣播系統發布針對性告警,形成“監測-預警-廣播”的自動化應急流程。
四、走向“系統監控即服務”:智慧安防新趨勢
隨著云計算、物聯網、大數據技術的發展,礦山安全系統正從傳統的設備采購模式向“監控即服務”模式演進。這一模式意味著:
- 服務化運營:專業服務商提供從系統設計、建設、運維到數據分析的一體化服務,礦山企業按需訂閱,減輕自身技術維護負擔。
- 數據驅動決策:通過對海量監控數據的云端分析與挖掘,提供更精準的安全風險研判、設備健康度評估和優化管理建議。
- 遠程專家支持:借助網絡,可實現遠程診斷、專家實時在線指導應急處置,提升響應效率與專業性。
- 系統持續進化:服務模式便于系統功能的快速迭代和升級,使礦山安全防護體系能夠持續適應新的技術標準和安防需求。
###
礦用廣播通訊系統與金屬礦山監控系統,作為礦山安全避險六大系統中的關鍵組成部分,其有效集成與高效運行是礦山安全生產的重要防線。而擁抱“安全系統監控服務”這一新模式,更是礦山企業實現安全管理智能化、精細化、可持續化的必然選擇。唯有將堅固的設備系統與專業的運營服務深度融合,方能最大程度地“抖”落安全隱患,真正筑牢礦山安全生產的銅墻鐵壁,守護每一名礦工平安歸家之路。
如若轉載,請注明出處:http://www.luannve.cn/product/60.html
更新時間:2026-06-14 15:14:29